
RAG技术整理
核心原理和流程
Step1,数据预处理
• 知识库构建:收集并整理文档、网页、数据库等多源数据,构
建外部知识库。
• 文档分块:将文档切分为适当大小的片段(chunks),以便后
续检索。分块策略需要在语义完整性与检索效率之间取得平衡。
• 向量化处理:使用嵌入模型(如BGE、M3E、Chinese-Alpaca-2
等)将文本块转换为向量,并存储在向量数据库中
Step2,检索阶段
查询处理:将用户输入的问题转换为向量,并在向量数据库中进
行相似度检索,找到最相关的文本片段。
重排序:对检索结果进行相关性排序,选择最相关的片段作为生
成阶段的输入
Step3,生成阶段
上下文组装:将检索到的文本片段与用户问题结合,形成增强的
上下文输入。
生成回答:大语言模型基于增强的上下文生成最终回答。
RAG的步骤:
Indexing => 如何更好地把知识
存起来。
Retrieval => 如何在大量的知识
中,找到一小部分有用的,给
到模型参考。
Generation => 如何结合用户的
提问和检索到的知识,让模型
生成有用的答案。
embedding 模型选择
通用文本嵌入模型
BGE-M3(智源研究院)
• 特点:支持100+语言,输入长度达8192 tokens,融合密集、稀疏、
多向量混合检索,适合跨语言长文档检索。
• 适用场景:跨语言长文档检索、高精度RAG应用。
text-embedding-3-large(OpenAI)
• 特点:向量维度3072,长文本语义捕捉能力强,英文表现优秀。
• 适用场景:英文内容优先的全球化应用。
Jina-embeddings-v2(Jina AI)
• 特点:参数量仅35M,支持实时推理(RT<50ms),适合轻量化
部署。
• 适用场景:轻量级文本处理、实时推理任务。
中文嵌入模型
xiaobu-embedding-v2
• 特点:针对中文语义优化,语义理解能力强。
• 适用场景:中文文本分类、语义检索。
M3E-Turbo
• 特点:针对中文优化的轻量模型,适合本地私有化部署。
• 适用场景:中文法律、医疗领域检索任务。
stella-mrl-large-zh-v3.5-1792
• 特点:处理大规模中文数据能力强,捕捉细微语义关系。
• 适用场景:中文文本高级语义分析、自然语言处理任务。
指令驱动与复杂任务模型
gte-Qwen2-7B-instruct(阿里巴巴)
• 特点:基于Qwen大模型微调,支持代码与文本跨模态检索。
• 适用场景:复杂指令驱动任务、智能问答系统。
E5-mistral-7B(Microsoft)
• 特点:基于Mistral架构,Zero-shot任务表现优异。
• 适用场景:动态调整语义密度的复杂系统。
企业级与复杂系统
BGE-M3(智源研究院)
• 特点:适合企业级部署,支持混合检索。
• 适用场景:企业级语义检索、复杂RAG应用。
E5-mistral-7B(Microsoft)
• 特点:适合企业级部署,支持指令微调。
• 适用场景:需要动态调整语义密度的复杂系统。
相比于LLM,RAG的优势在哪里
效率与成本:LLM处理长上下文时计算资源消耗大,响应时间增加。RAG通过检索相关片段,减少输入长度。
知识更新:LLM的知识截止于训练数据,无法实时更新。RAG可以连接外部知识库,增强时效性。
可解释性:RAG的检索过程透明,用户可查看来源,增强信任。LLM的生成过程则较难追溯。
定制化:RAG可针对特定领域定制检索系统,提供更精准的结果,而LLM的通用性可能无法满足特定需求。
数据隐私:RAG允许在本地或私有数据源上检索,避免敏感数据上传云端,适合隐私要求高的场景。
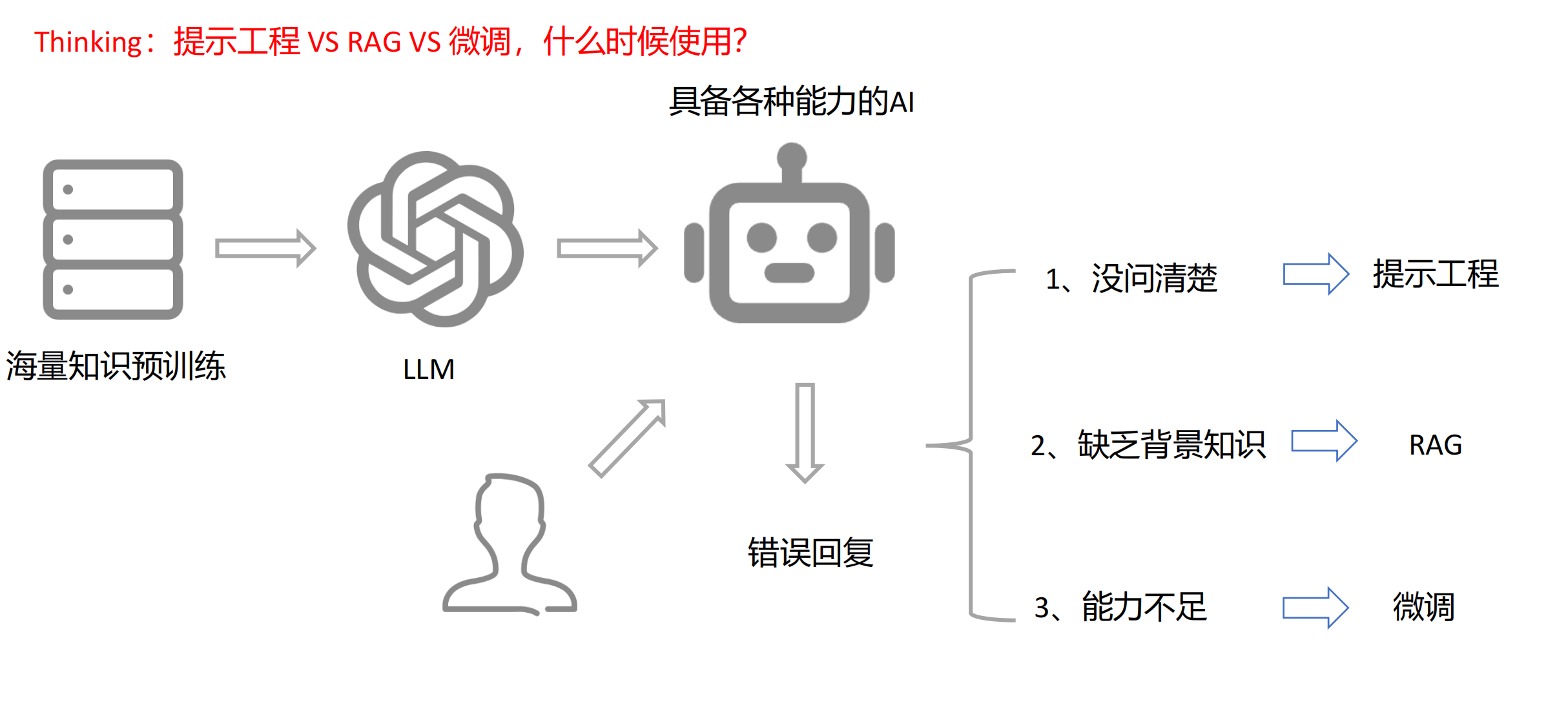
如果你提了一个问题,大语言模型并没有很好的回答我们。
出现问题的原因有以下几个:
1.你的问题很模糊,不够精确,所以大语言模型并不能很好的回答我们,涉及提示词工程。
2.大语言模型缺少及时的知识,或者知识不够新,所以模型不能很好的回答我们,涉及RAG技术(本地知识库的搭建),
3.模型里面的内容是有问题的,所以模型不能很好的回答我们,涉及模型的微调。
外部知识
embedding 模型选择
https://huggingface.co/spaces/mteb/leaderboard